
ZIP 解析差异
ZIP 解析差异
1. 引言:
目前市面上关于 ZIP 研究较多的还是类似于 ZIP slip 或者 ZIP bomb 这种漏洞,此次分享主要针对 ZIP 解析歧义
无处不在的容器技术: ZIP 格式(最初由 PKWARE 在 1989 年发布)已经演变成了一种通用的容器格式 。许多我们熟悉的现代文件格式,本质上都是经过伪装的 ZIP 包:
办公文档:Microsoft Office (
.docx,.xlsx,.pptx) 和 OpenOffice (.odt) 。
移动应用:Android 应用程序 (
.apk) 。代码运行环境:Java 归档 (
.jar,.war) 。浏览器扩展:Chrome (
.crx), Firefox (.xpi) 。其他:电子书 (
.epub), 3D 打印格式 (.3mf) , phar .....
生态系统的碎片化: 尽管 ZIP 如此重要,但它的规范文档 APPNOTE.TXT 却写得非常随意,留下了大量未定义的细节 。即便是 2015 年发布的 ISO/IEC 21320-1 标准,也未能解决这些历史遗留的模糊性 。
现状是:如果你让 50 个不同的程序解析同一个 ZIP 文件,你可能会得到 50 种略微不同的结果 。这种“不一致性”就是安全漏洞滋生的温床。
2. ZIP 文件
一个标准的 ZIP 文件由三个核心部分组成,这也是后续所有攻击的基础:
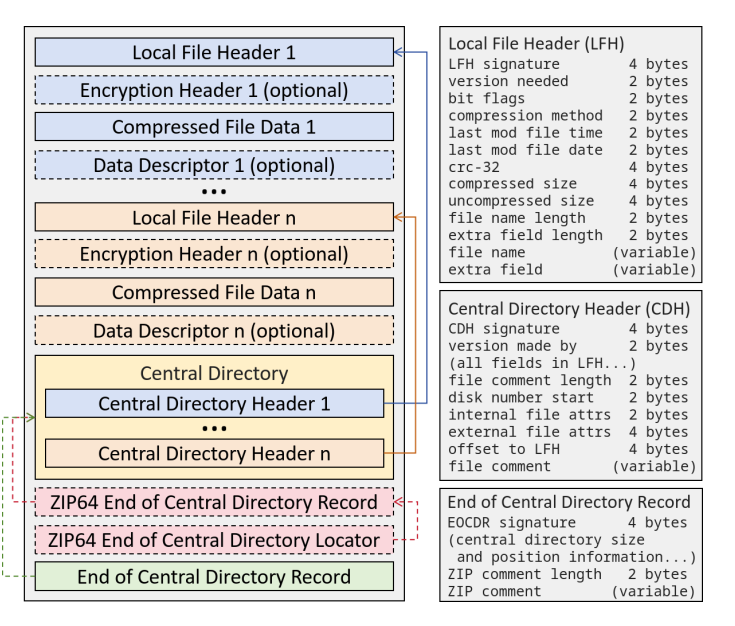
2.1 核心组件
- 本地文件头 (Local File Header, LFH)
- 位置:与被压缩的文件数据紧邻,位于文件的前部或中部。
- 内容:包含文件名、压缩方法、压缩前/后大小、CRC32 校验和等元数据。
- 用途:主要用于流式处理(一边下载一边解压)。
- 中央目录 (Central Directory, CD)
- 位置:位于文件的尾部。
- 组成:由一系列中央目录头 (Central Directory Header, CDH) 组成。
- 内容:包含了 LFH 中的所有信息(文件名、大小等),外加文件属性、文件在磁盘中的偏移量(Offset to LFH)。
- 用途:作为“目录索引”,支持随机访问。解压软件通常先读这里,以便快速列出文件列表而无需读取整个文件 。
- 中央目录结束记录 (End of Central Directory Record, EOCDR)
- 位置:文件的最末尾。
- 内容:标记着 ZIP 文件的结束。包含中央目录的大小、位置、条目数量以及 ZIP 文件的注释。
- 关键作用:它是标准解析器解析 ZIP 文件的入口点 。
我们也可以自己做一个简单的 ZIP 去在 010 Editor 中去查看一下
import zipfile
# 创建一个不压缩的zip文件,方便分析
# compression=zipfile.ZIP_STORED 表示仅打包,不压缩
with zipfile.ZipFile('normal.zip', 'w', compression=zipfile.ZIP_STORED) as zf:
# 写入一个名为 "flag.txt" 的文件,内容只有 5 个字节
zf.writestr('flag.txt', 'Happy New Year!')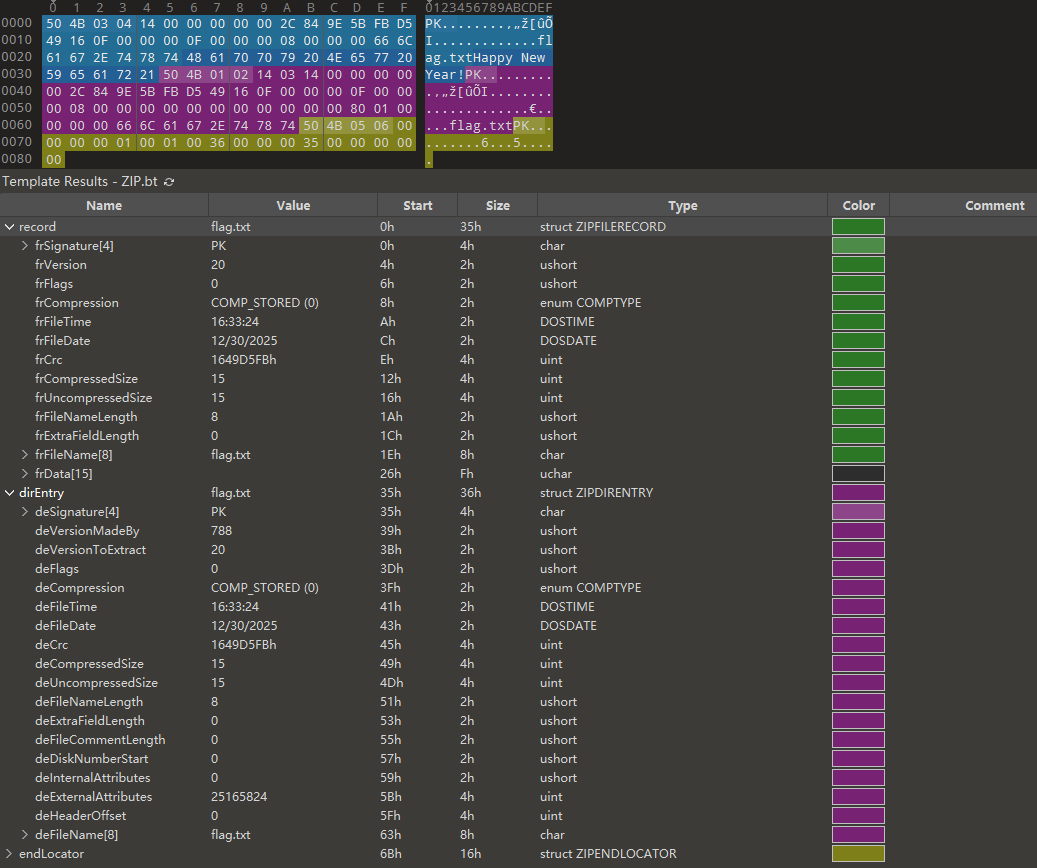
对应到官方规范的标准术语的话,可能更常见这样的形式
struct ZIPFILERECORD record[]
对应 Local File Header + File Data (文件的实际存储区域),可有多个 record 组成
struct ZIPDIRENTRY dirEntry[]
对应 Central Directory (中央目录)
struct ZIPENDLOCATOR endLocator
对应 End of Central Directory Record (EOCD),也就是整个 ZIP 文件的结尾,这个结构体里记录了 Central Directory 在文件中的偏移量。操作系统是先读这里,依靠它来Locate中央目录的位置,所以作者给它起名叫
Locator。
2.2 关键设计缺陷:数据冗余
ZIP 格式最大的设计特点(也是最大的弱点)在于数据冗余。
- 元数据存了两份:文件名、文件大小、CRC32 等关键信息,在 LFH 和 CDH 中都存储了一份 。
- 初衷:CDH 用于快速检索,LFH 用于数据恢复或流式处理。
- 隐患:如果 LFH 说这个文件大小是 100MB,而 CDH 说这个文件大小是 1KB,解析器该信谁的? 。
3. 两种截然不同的解析范式
正是由于上述的结构特点,导致了现实世界中存在两种完全不同的 ZIP 解析逻辑。攻击者正是利用这两种逻辑的差异来实施攻击。
3.1 标准解析模式 (Standard / Random Access Parsing)
这是大多数归档工具(如 WinRAR, 7-Zip)和操作系统文件管理器的解析方式。
- 流程:
- 定位尾部:扫描文件末尾,寻找 EOCDR 签名 (
0x06054b50) 。 - 读取目录:根据 EOCDR 提供的信息,跳转到 中央目录 (CD) 的位置 。
- 定位文件:遍历 CD 中的 CDH,获取文件列表。
- 提取数据:根据 CDH 记录的偏移量,跳转到对应的 LFH 处提取数据 。
- 定位尾部:扫描文件末尾,寻找 EOCDR 签名 (
- 特点:高度依赖文件尾部的 EOCDR 和 CDH,往往忽略 LFH 中的元数据,甚至可能根本不检查 LFH 的完整性。
3.2 流式解析模式 (Streaming Parsing)
这是网络设备(防火墙、安全网关)、Java JarInputStream、反病毒引擎常用的方式,因为它们可能无法回溯读取文件。
- 流程:
- 从头开始:从文件第 0 字节开始读取。
- 顺序扫描:寻找 LFH 签名 (
0x04034b50)。 - 处理数据:读取 LFH 后紧接着读取压缩数据,直到下一个 header 。
- 忽略尾部:通常完全忽略中央目录和 EOCDR。
- 特点:只信任 LFH,完全“看不见”中央目录里的信息。
3.3 语义差异的诞生
攻击面:如果攻击者构造一个 ZIP 文件,让它的 LFH 序列 和 中央目录 (CD) 描述完全不同的内容,就会发生:
流式解析器(杀毒软件) 看到的是 A(无害文件)。
标准解析器(解压工具) 看到的是 B(恶意软件)。
4. 14种解析歧义
最新的研究(USENIX Security '25)利用差分模糊测试工具 ZIPDIFF,对 19 种编程语言的 50 个 ZIP 解析器进行了系统性测试,发现了 14 种解析歧义,并将它们归为三大类。这些歧义正是攻击者利用“语义鸿沟”的弹药库。
4.1 第一类:冗余元数据 (Redundant Metadata)
这一类歧义源于 ZIP 格式在 LFH 和 CDH 中存储了重复的信息。当这两处信息不一致时,解析器该听谁的?
- A1 压缩方法混淆 (Compression Method Confusion):CDH 说文件是“压缩的”,LFH 说文件是“存储的(未压缩)”。聪明的解析器可能解压出无害数据,而“笨”解析器直接把压缩数据当作原始内容,导致内容完全不同。
- A2 文件大小混淆 (File Size Confusion):压缩大小、未压缩大小在 CDH、LFH、甚至数据描述符(Data Descriptor)中都有记录。攻击者可以利用 CRC32 的非加密特性,填充数据以欺骗大小检查。
- A3 文件名混淆 (Filename Confusion):除了标准的 ASCII 文件名,ZIP 还支持 Unicode 路径扩展字段 (UP)。有的解析器优先读 UP,有的只读标准字段,导致看到的文件名不同。
- A4 伪造目录 (Fake Directory):一个条目是文件还是目录?有的看路径是否以
/结尾,有的看外部文件属性。这可能导致一个恶意文件被误认为是目录而跳过扫描。 - A5 伪造加密 (Fake Encryption):如果 LFH 标记为加密,而 CDH 标记为未加密,解析器可能因为“不支持加密”而放弃扫描,或者反过来直接提取出明文内容。
4.2 第二类:文件路径处理 (File Path Processing)
这一类歧义涉及解析器如何理解和规范化文件路径。
- B1 重复文件 (Duplicate Files):如果 ZIP 里有两个名为
config.xml的文件,解析器是取第一个还是最后一个?这决定了受害者看到的是正常配置还是恶意配置。 - B2 非法字符 (Invalid Characters):路径中包含空字节或控制字符时,有的解析器会截断,有的会替换,导致最终路径不同。
- B3 路径规范化 (Path Canonicalization):
./,../,//等路径写法,不同解析器的处理逻辑千差万别。 - B4 大小写敏感性 (Case Sensitivity):Windows 往往不区分大小写,而 Linux 区分。
Malware.exe和malware.exe在某些环境下被视为同一个文件,在另一些则不是。
4.3 第三类:ZIP 结构定位 (ZIP Structure Positioning)
这是最底层也最危险的一类,涉及解析器如何找到 ZIP 文件的各个部分。
- C1 流式解析差异 (Streaming Parsing):流式解析器(如杀毒软件)只看 LFH。攻击者可以构造没有 CDH 的 LFH,或者通过数据描述符混淆文件边界,让流式解析器“看走眼”。
- C2 EOCDR 选择 (EOCDR Selection):ZIP 允许文件尾部有注释,攻击者可以在注释里伪造一个假的 EOCDR。解析器是从后往前找第一个,还是找最“像”的一个?
- C3 CDH 数量混淆 (CDH Count Confusion):EOCDR 里的记录数量字段只有 16 位(最多 65535)。超过这个数怎么办?不同解析器的处理方式(如取模)可能导致看到的目录结构完全不同。
- C4 CD 与 LFH 偏移量混淆 (CD & LFH Offset Confusion):自解压文件会在 ZIP 前面加一段代码。解析器是否能正确计算偏移量?
- C5 ZIP64 EOCD 处理 (ZIP64 EOCD Processing):为了支持大文件,ZIP64 引入了新的结束记录。解析器是优先信 ZIP64 还是普通 EOCDR?这里充满了不一致性。
5.模拟演示
5.1 Python
5.2 PHP
PHP 的 ZipArchive 扩展是通过封装 libzip 库来实现的
5.3 unzip
6. 一些Real-world攻击场景
这些理论上的歧义在现实世界中有着惊人的破坏力。
6.1 安全邮件网关绕过
- 场景:攻击者发送带有恶意 ZIP 附件的邮件。
- 原理:网关上的杀毒软件通常使用流式解析,或者依赖 CDH 中的文件大小。攻击者利用 A2 文件大小混淆,将 CDH 中的大小改为 1 字节,骗过杀毒软件。
- 后果:用户收到邮件,使用标准解压软件(如 WinRAR)打开,恶意软件被完整解压并执行。Gmail 等主流服务都曾受此影响。
6.2 Office 文档内容欺骗
- 场景:学生提交论文给查重系统,或者员工提交报告给老板。
- 原理:Office 文档(.docx)本质上是 ZIP。攻击者利用 B1 重复文件 或 C5 ZIP64 处理差异,在文档中放入两份
document.xml。 - 后果:查重系统看到的是一份“原创”的纯洁文档,而老师用 Word 打开看到的却是抄袭的内容。或者反之,让 AI 助手看到错误的信息。
6.3 LibreOffice 文档签名伪造
- 场景:攻击者篡改已签名的文档,但签名验证依然通过。
- 原理:LibreOffice 的签名验证器和文档显示器使用了不同的解析逻辑(正常模式 vs 恢复模式)。利用 A3 文件名混淆,验证器检查的是原始文件,而显示器展示的是篡改后的文件。
- 后果:用户看到一份内容被篡改的文档,但软件却提示“签名有效,文档未被修改”。
6.4 Spring Boot 嵌套 JAR 签名伪造
- 场景:Java 应用中常见的嵌套 JAR 包(JAR 里套 JAR)。
- 原理:Spring Boot 加载器使用标准解析,而 Java 的签名验证 (
JarInputStream) 使用流式解析。利用 C1 流式解析差异,攻击者可以构造一个 JAR,让签名验证器看到合法的签名文件,而加载器加载恶意的类文件。 - 后果:恶意代码在受信任的签名保护下运行。
6.5 VS Code 扩展 ID 冒充
- 场景:攻击者发布恶意扩展,冒充知名扩展。
- 原理:VS Code 扩展市场和 VS Code 客户端对 A3 Unicode 路径 的处理不一致。
- 后果:市场认为这是
attacker.bar(合规),但用户安装时,VS Code 客户端认为这是bob.foo(知名扩展),从而覆盖正版扩展,实施供应链攻击。
7. 防御与未来
面对如此广泛的生态系统碎片化,防御并非易事:
- 统一解析器 (Use the same parser):理想情况下,整个处理链路使用同一个解析库。但在多厂商协作的环境下(如邮件网关+终端用户)很难实现。
- 规范化重打包 (Normalize the ZIP file):在网关处将 ZIP 解压并重新打包。这能消除大部分结构性歧义,但开销较大。
- 拒绝歧义模式 (Identify ambiguous patterns):检测并拒绝包含重叠条目、不一致元数据的 ZIP 文件。虽然可能误伤一些合法的非标准文件,但能显著提高安全性。
- 多重解析检测 (Incorporate different parsing logics):使用多种解析逻辑扫描同一个文件,只要有一个发现问题就报警。