
MCP 概念简述、开发实践与安全风险
很早就想去开发这个去做一点有意思的事但是当时去实习了,暑假回来当成周会的分享内容写一下,开发的 qqbot 结合 MCP 还是蛮好用的,感谢锦恢开发的 OpenMCP 帮助我更好的上手。
What is MCP
MCP 起源于 2024 年 11 月 25 日 Anthropic 发布的文章:Introducing the Model Context Protocol。
MCP (Model Context Protocol,模型上下文协议)定义了应用程序和 AI 模型之间交换上下文信息的方式。这使得开发者能够以一致的方式将各种数据源、工具和功能连接到 AI 模型(一个中间协议层),就像 USB-C 让不同设备能够通过相同的接口连接一样。MCP 的目标是创建一个通用标准,使 AI 应用程序的开发和集成变得更加简单和统一。
最经典的一张图示:
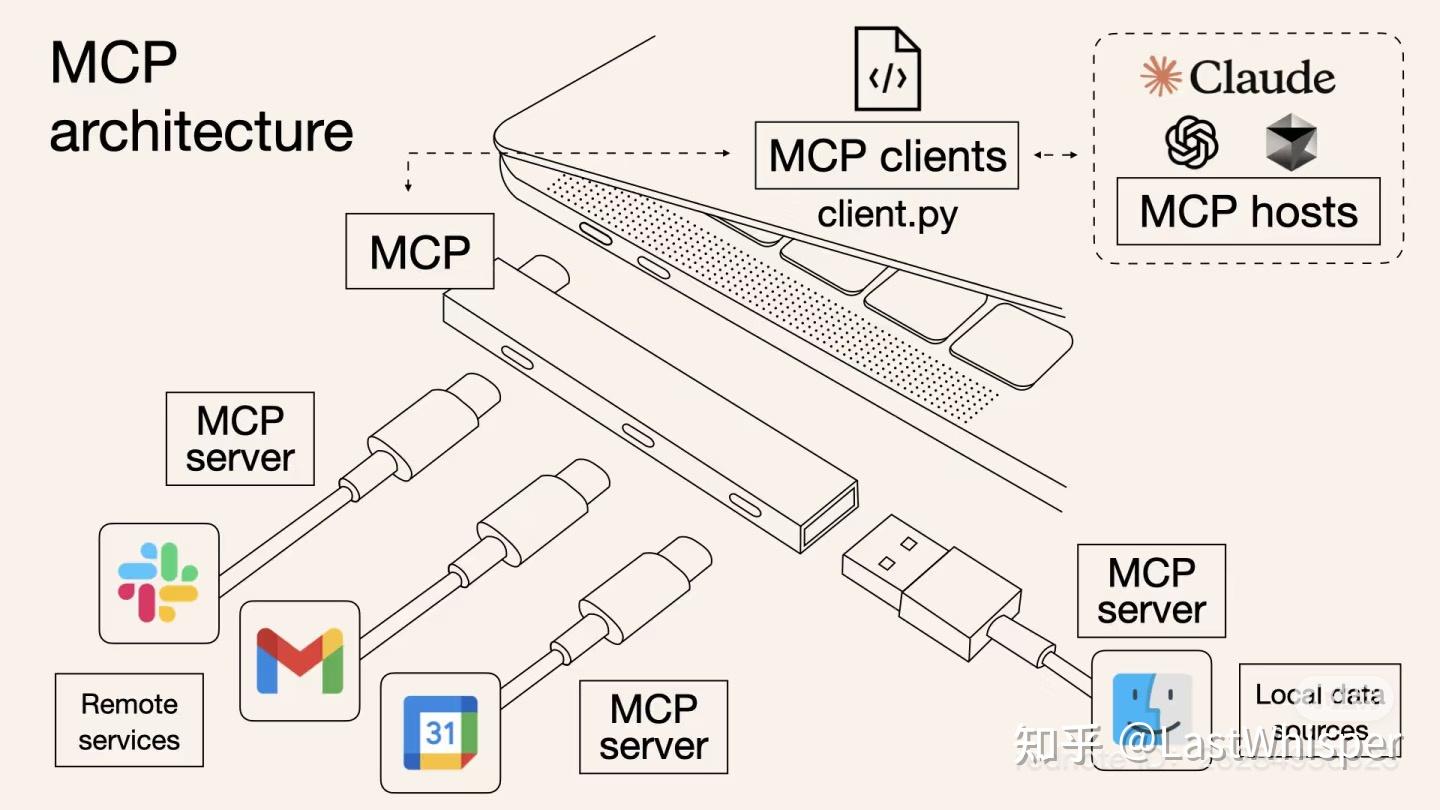
The Evolution of Prompt Engineering
模型-内容-提示(MCP)是提示工程(prompt engineering)发展到一定阶段的必然产物。事实证明,为模型提供更结构化的上下文信息,能显著提升其表现。在构建提示词时,我们常常希望能够引入更具体的信息,例如来自本地文件、数据库或实时网络数据,以帮助模型更好地理解真实场景中的问题。(这些在我后面的开发中都有体现)
在 MCP 出现之前,我们通常需要手动将这些信息从数据库或工具中筛选并复制粘贴到提示词中。当问题变得复杂时,这种手动操作的局限性就日益凸显。
为了解决这一痛点,许多大型语言模型(LLM)平台推出了 函数调用(function call) 功能,允许模型在需要时调用预定义函数来获取数据或执行操作,从而实现一定程度的自动化。
然而,函数调用也有其局限性,最主要的一点是其平台强依赖性。不同 LLM 平台的函数调用 API 实现差异很大,例如 OpenAI 和 Google 的函数调用方式并不兼容。这导致开发者在切换模型时需要重写大量代码,增加了适配成本。此外,还存在数据安全和交互性等方面的挑战。
数据和工具本身是客观存在的,我们真正需要的是一个更智能、更统一的方式来连接它们与模型。MCP 正是基于此需求而生,它就像一个通用适配器,能够帮助 LLM 轻松获取数据和调用工具。MCP 的核心优势体现在以下几点:
- 丰富的生态: MCP 提供了大量现成的插件,AI 模型可以直接调用。
- 统一性: 不受限于特定 AI 模型,任何支持 MCP 的模型都可以灵活切换。
- 数据安全: 敏感数据可以留在本地,不必全部上传。
MCP Architecture
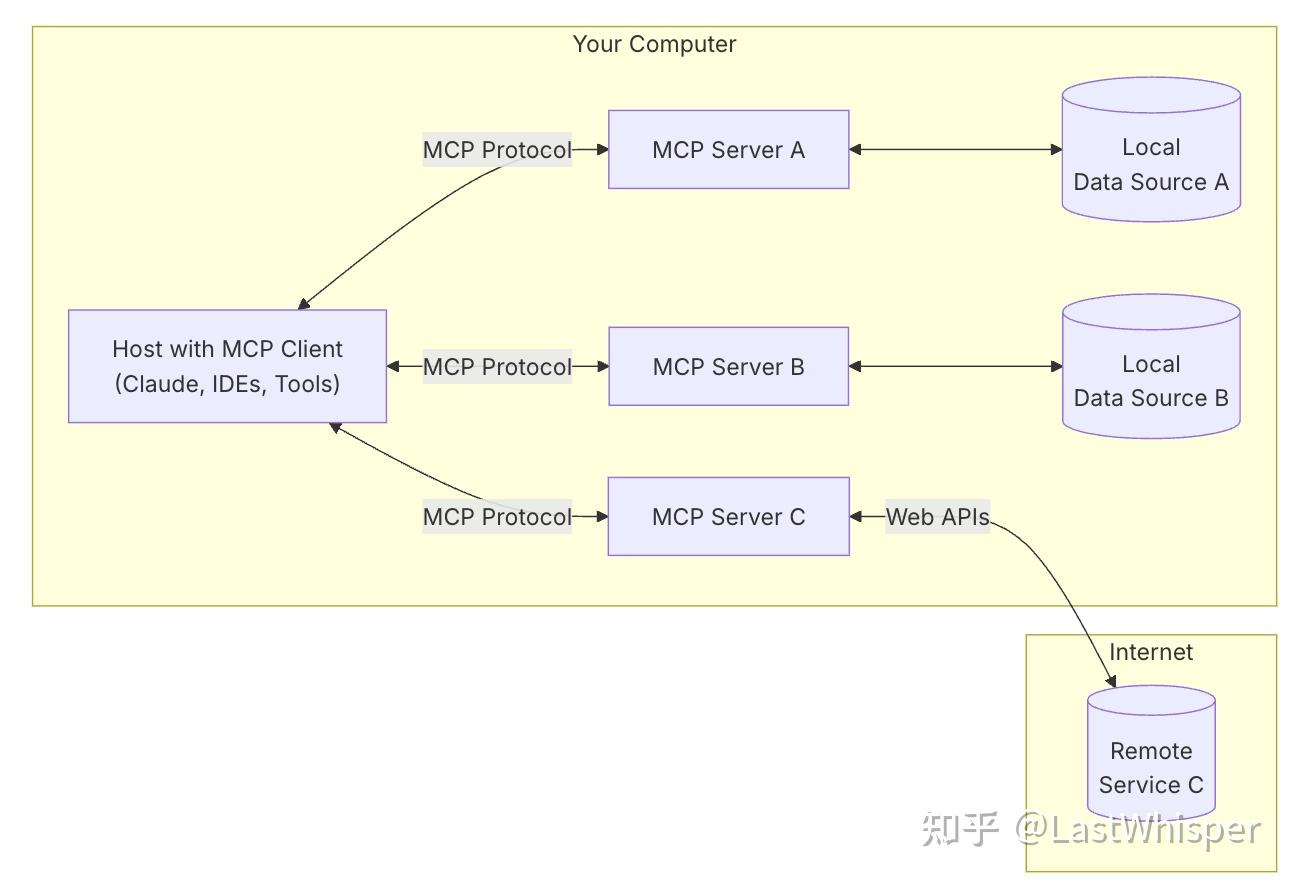
模型-内容-提示(MCP)的核心架构由 Host、Client 和 Server 三个关键组件组成。它们协同工作,使大语言模型(LLM)能够与外部工具和数据源进行交互。
让我们以一个具体场景来理解这个过程:当你在使用 Claude Desktop (Host) 询问“我桌面上都有哪些文档?”时,会发生以下流程:
- Host:作为前端应用,Claude Desktop 接收你的提问,并将其发送给 Claude 模型。
- Client:Claude 模型在处理你的问题后,判断需要访问你的文件系统来获取信息。此时,内置于 Host 的 MCP Client 会被激活,负责寻找并连接合适的服务端。
- Server:与文件系统相关的 MCP Server 被调用。它会执行实际的文件扫描操作,访问你的桌面目录,并返回找到的文档列表。
整个过程可以概括为:你的提问 → Host → LLM → 激活 Client → 连接 Server → 执行操作 → 返回结果 → LLM 生成回答 → Host 显示结果。
这种分离式设计的好处在于,开发者只需专注于开发特定的 MCP Server,而无需关注前端应用(Host)和连接器(Client)的实现细节,极大地提高了开发的灵活性和效率。
How Models Select and Use Tools
**MCP Server **中通常包含了一些需要使用的 tools,大语言模型(LLM)是如何决定要调用哪些工具的? 幸好,Anthropic 为我们详细阐述了 Claude 选择工具的过程。
当用户提出一个问题时,整个流程是这样的:
- 用户提问: 客户端应用(如 Claude Desktop 或 Cursor)接收用户的问题,并将其发送给 Claude 模型。
- 模型决策: Claude 分析其可用的工具集,并决定使用一个或多个工具来辅助回答问题。
- 工具调用: 客户端通过 MCP Server 执行所选的工具。
- 结果返回: 工具的执行结果被送回给 Claude。
- 生成回答: Claude 结合工具的执行结果,构建最终的提示词并生成自然语言的回应。
- 展示结果: 最终的回应在客户端上展示给用户。
值得注意的是,MCP Server 是由 Claude 主动选择并调用的。这引发了另一个问题:Claude 具体是如何做出这个选择的? 它是否可能“幻觉”出一些不存在的工具?
为了更深入地探索这个机制,我们分析了其底层源码。这个调用过程可以被分解为两个主要步骤:
- 步骤一: LLM(Claude)确定要使用哪些 MCP Server。
- 步骤二: 执行相应的 MCP Server,并对执行结果进行处理。
这个过程可以用一个简单的图示来帮助理解。
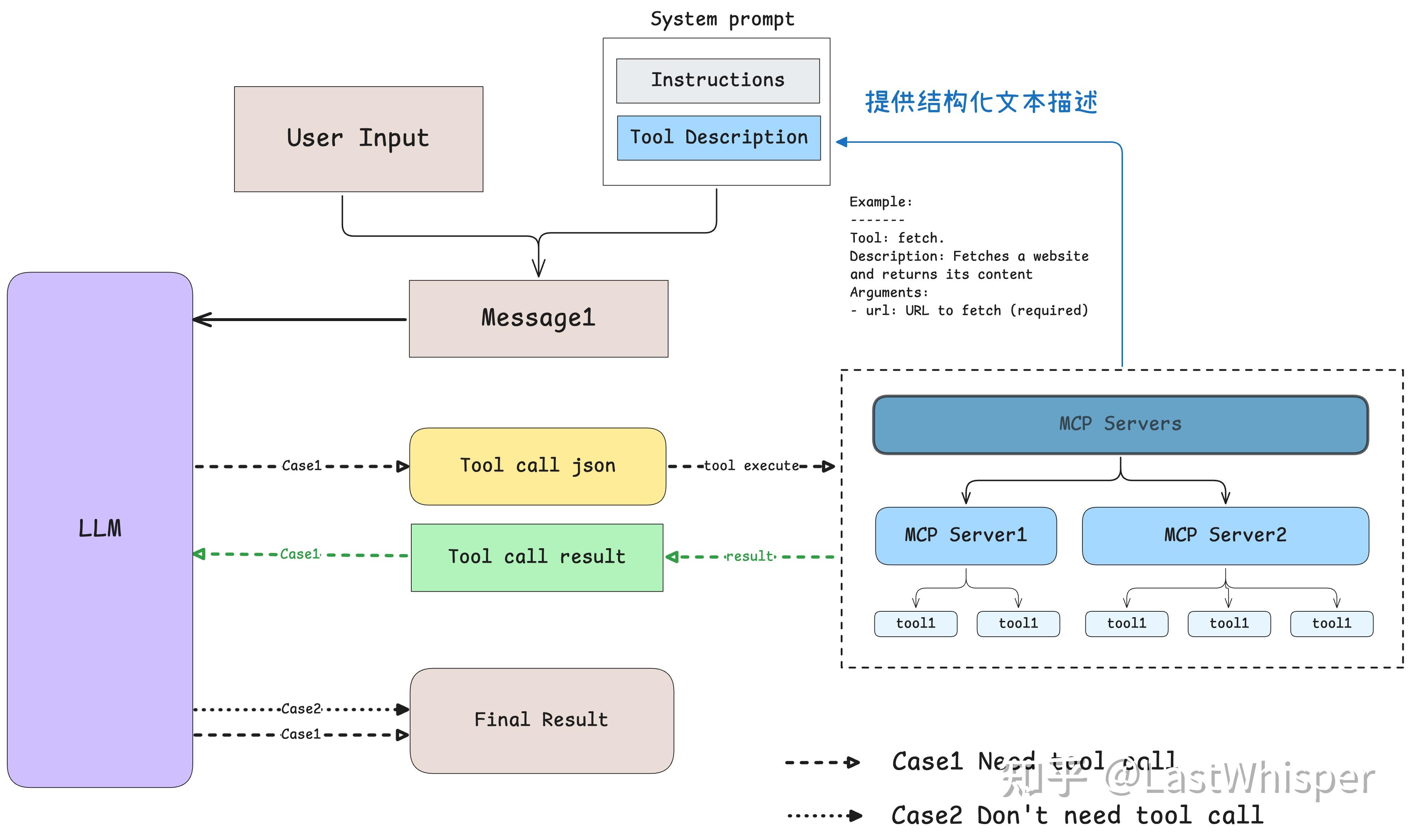
为了理解模型如何确定该使用哪些工具,我们可以从 MCP 官方提供的客户端示例入手。通过简化和分析其核心代码,我们发现模型是通过**提示词(prompt)**来完成工具选择的。
具体而言,我们以文本形式向模型传递可用工具的详细描述,包括其功能和使用方法。模型通过理解这些描述,结合当前的实时情境,来决定最适合使用的工具。
这个过程可以概括为:提供工具描述 → 模型理解 → 模型选择。这表明,模型的工具选择能力很大程度上依赖于我们提供的提示词质量。
我们这里简化了一些基于 python 的 MCP SDK(FastMCP) 实现来理解工具调用
async def start(self):
# 初始化所有的 mcp server
for server in self.servers:
await server.initialize()
# 获取所有的 tools 命名为 all_tools
all_tools = []
for server in self.servers:
tools = await server.list_tools()
all_tools.extend(tools)
# 将所有的 tools 的功能描述格式化成字符串供 LLM 使用
# tool.format_for_llm() 我放到了这段代码最后,方便阅读。
tools_description = "\n".join(
[tool.format_for_llm() for tool in all_tools]
)
# 这里就不简化了,以供参考,实际上就是基于 prompt 和当前所有工具的信息
# 询问 LLM(Claude) 应该使用哪些工具。
system_message = (
"You are a helpful assistant with access to these tools:\n\n"
f"{tools_description}\n"
"Choose the appropriate tool based on the user's question. "
"If no tool is needed, reply directly.\n\n"
"IMPORTANT: When you need to use a tool, you must ONLY respond with "
"the exact JSON object format below, nothing else:\n"
"{\n"
' "tool": "tool-name",\n'
' "arguments": {\n'
' "argument-name": "value"\n'
" }\n"
"}\n\n"
"After receiving a tool's response:\n"
"1. Transform the raw data into a natural, conversational response\n"
"2. Keep responses concise but informative\n"
"3. Focus on the most relevant information\n"
"4. Use appropriate context from the user's question\n"
"5. Avoid simply repeating the raw data\n\n"
"Please use only the tools that are explicitly defined above."
)
messages = [{"role": "system", "content": system_message}]
while True:
# Final... 假设这里已经处理了用户消息输入.
messages.append({"role": "user", "content": user_input})
# 将 system_message 和用户消息输入一起发送给 LLM
llm_response = self.llm_client.get_response(messages)
... # 后面和确定使用哪些工具无关
class Tool:
"""Represents a tool with its properties and formatting."""
def __init__(
self, name: str, description: str, input_schema: dict[str, Any]
) -> None:
self.name: str = name
self.description: str = description
self.input_schema: dict[str, Any] = input_schema
# 把工具的名字 / 工具的用途(description)和工具所需要的参数(args_desc)转化为文本
def format_for_llm(self) -> str:
"""Format tool information for LLM.
Returns:
A formatted string describing the tool.
"""
args_desc = []
if "properties" in self.input_schema:
for param_name, param_info in self.input_schema["properties"].items():
arg_desc = (
f"- {param_name}: {param_info.get('description', 'No description')}"
)
if param_name in self.input_schema.get("required", []):
arg_desc += " (required)"
args_desc.append(arg_desc)
return f"""
Tool: {self.name}
Description: {self.description}
Arguments:
{chr(10).join(args_desc)}
"""那 tool 的描述和代码中的 input_schema 是从哪里来的呢?通过进一步分析 MCP 的 Python SDK 源代码可以发现:大部分情况下,当使用装饰器 @mcp.tool() 来装饰函数时,对应的 name 和 description 等其实直接源自用户定义函数的函数名以及函数的 docstring 等。
这里拿一个简单的天气 MCP 图示
总之就是模型是通过 prompt engineering,即提供所有工具的结构化描述和 few-shot 的 example 来确定该使用哪些工具。另一方面,Anthropic 肯定对 Claude 做了专门的训练(毕竟是自家协议,Claude 更能理解工具的 prompt 以及输出结构化的 tool call json 代码)
但是正因这个调用原理,会导致后文会提到的一些安全隐患,我们放在第三部分再讲
最后工具执行的结果 result 会和 system prompt 和用户消息一起重新发送给模型,请求模型生成最终回复。
Develop Your Own Application With MCP
我在调试工具上没有选择 Claude Desktop,选了一个国内开源的 MCP-Client OpenMCP
Vulnerability in MCP - Tool Poisoning Attacks
我们在上文分析工具调用时留下了一个问题,关于工具调用背后的安全隐患,如果我们在工具描述中加一些信息去操控 LLM 去执行预期功能外的恶意行为呢?这就是工具中毒攻击(Tool Poisoning Attacks)
什么是工具中毒攻击 (TPA)?
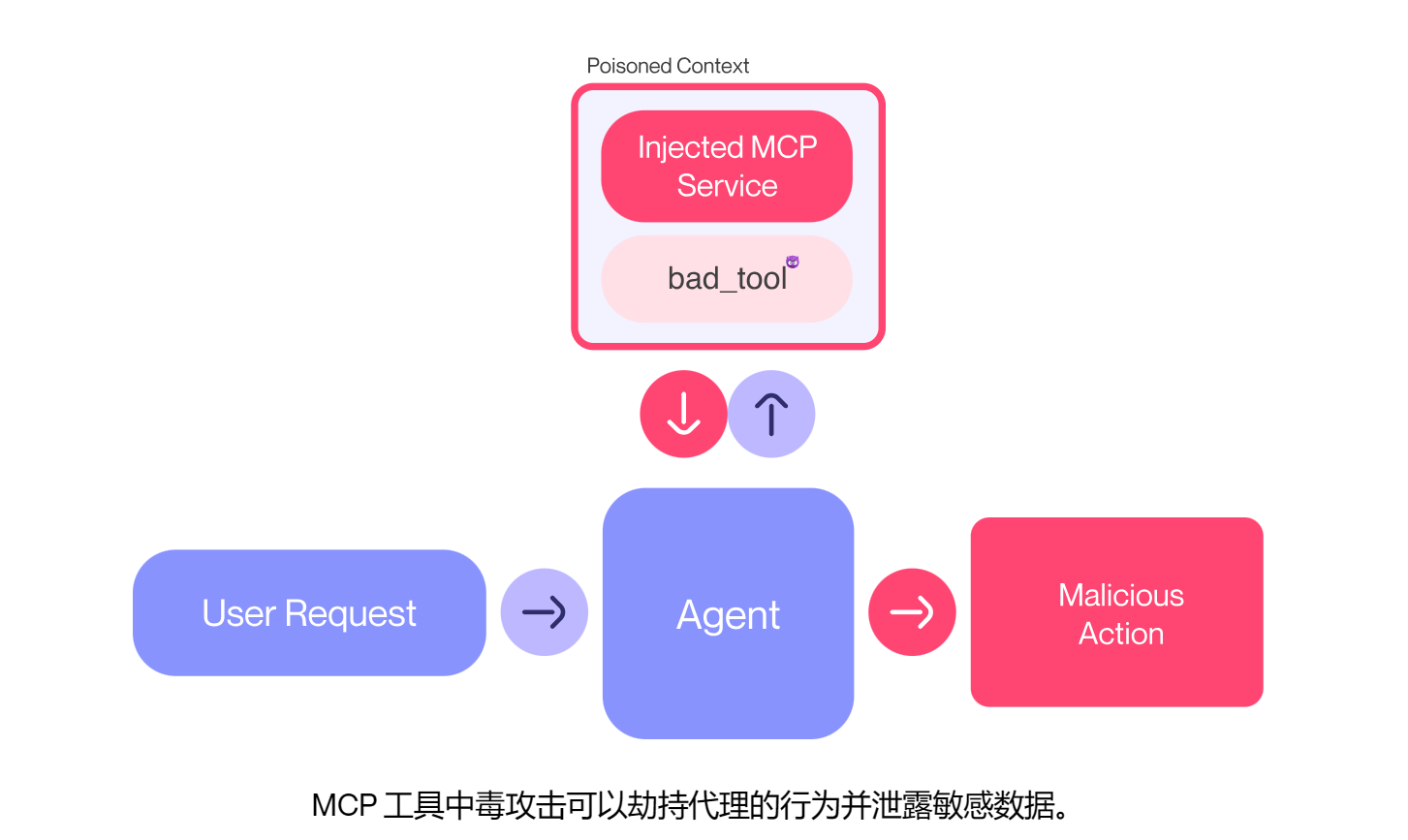
工具中毒攻击是指恶意指令嵌入到 MCP 工具描述中,这些指令对用户不可见,但对 AI 模型可见。这些隐藏的指令可以操纵 AI 模型,使其在用户不知情的情况下执行未经授权的操作。
MCP 的安全模型假设工具描述是可信且良性的。然而,我们的实验表明,攻击者可以伪造包含以下指令的工具描述:
- 指示 AI 模型直接访问敏感文件(如 SSH 密钥、配置文件、数据库等)
- 指示人工智能提取和传输这些数据,同时向用户隐藏这些操作。
- 通过隐藏工具参数和输出的过于简单的 UI 表示,造成用户所看到的内容与 AI 模型所做的事情之间的脱节。
References
MCP (Model Context Protocol),一篇就够了。